This is an R Notebook: a document containing code and text. A live version can be run through MyBinder, which will spin up a copy of R-studio for you to use, and the source code is available on GitHub.
Clicking on the MyBinder link above will bring you to an R-Studio instance. In the ‘files’ window in the bottom-right of R-studio, open the document ‘r_and_wikidata.Rmd’, which will open this with a live copy of the code, which can be edited and re-run. Be warned it might still be a bit of a steep learning curve if you have no experience with R-studio/coding languages.
A few parts won’t run live: as we haven’t released the full dataset yet, one part of the code ‘cheats’, and uses a pre-processed object rather than loading up the full State Papers metadata to query directly. So you won’t be able to make changes to the section which pulls letters written by descendants of James I/VI. Also, the library ‘sf’ won’t install in the MyBinder build (it needs root priviledges to install a dependency), which means the maps cannot be made - at least for now. The rest, if loaded through myBinder or just directly through a local copy of R-Studio, can be adjusted to try other queries and cross-reference against the people records of the SPO and EMLO datasets.
Networking Archives and Wikidata
On the Networking Archives project we’ve been using Wikidata IDs as unique identifiers for some of our data types. At present, we use wikidata identities to disambiguate geographic places in our dataset and wikpedia links, where available, as a unique identifier for people records.
Wikidata is a knowledge graph: a type of database which stores information in what are known as triples. Data is stored as entities, which are connected by properties - which store the relationship between entities. For example: the entity ‘Henry Oldenburg’ is connected to the entity ‘Bremen’ by the property ‘Place of Birth’. Both Oldenburg and Bremen are themselves connected to many other entities through many other properties, resulting in a complex web of interrelated data.
In a dataset like that we’re making from the State Papers Online, a connection, via wikipedia links, to an external knowledge graph serves as a good starting point to fill in some basic biographical data for the people in the dataset.
Wikidata can be queried using a language called SPARQL. It’s based on the idea of triples, which consist of a subject, predicate and object and for simple queries you fill in two parts of the triple and ask the query to return the missing part. These statements can be linked together to construct complicated queries.
Accessing the Wikidata Query Service with R
SPARQL can be used directly through the Wikidata query service web page or via an API with a language such as R, as I’ve done here.
First, load the package needed, WikidataQueryServiceR, as well as some others to be used.
It’s a very simple package with one main function, query_wikidata(). Type the SPARQL query as a character string as the only argument to this function and it will return the relevant data as a dataframe. I’ll try to explain it using a query which fetches all Royal Society members with a date of birth before 1700.
my_query = query_wikidata("
SELECT DISTINCT ?item ?itemLabel
WHERE
{
?item wdt:P463 wd:Q123885.
?item wdt:P569 ?dob.
FILTER( ?dob <= '1700-01-01T00:00:00'^^xsd:dateTime).
SERVICE wikibase:label { bd:serviceParam wikibase:language 'en'. }
}")SELECT DISTINCT ?item ?itemLabel WHERE tells SPARQL to fetch everything with the curly brackets and store it in variables called item and itemlabel. Next we need to tell SPARQL what to put in those variables.
The query itself has three parts:
?item wdt:P463 wd:Q123885. this queries wikidata for all the entities which have the property ‘membership of’ (P463) linked to the entity ‘The Royal Society’ (Q123885).
?item wdt:P59 ?dob this queries those items for their date of birth (P59) and stores it as an item called ?dob.
FILTER( ?dob <= '1700-01-01T00:00:00'^^xsd:dateTime). this runs a filter and returns only items with a date of birth of before the first of January, 1700.
The result is an R dataframe - here are the first ten records:
my_query %>% head(10)## # A tibble: 10 x 2
## item itemLabel
## <chr> <chr>
## 1 http://www.wikidata.org/entity/Q2725340 Christopher Middleton
## 2 http://www.wikidata.org/entity/Q2557180 Archibald Campbell, 9th Earl of Argy…
## 3 http://www.wikidata.org/entity/Q2573060 Robert Spencer, 2nd Earl of Sunderla…
## 4 http://www.wikidata.org/entity/Q2577971 William Ball
## 5 http://www.wikidata.org/entity/Q2579338 William Houstoun
## 6 http://www.wikidata.org/entity/Q2702018 Edward Montagu, 2nd Earl of Manchest…
## 7 http://www.wikidata.org/entity/Q2708598 Philip Yorke, 1st Earl of Hardwicke
## 8 http://www.wikidata.org/entity/Q2855776 John Somers, 1st Baron Somers
## 9 http://www.wikidata.org/entity/Q2422246 Thomas Bates
## 10 http://www.wikidata.org/entity/Q3057690 Joseph MoxonWhat does this have to do with Networking Archives? Both datasets we’re using have extensive (though far from complete) linked data in the form of wikipedia links (for people) and wikidata entities (for places). Through this it is easy to join both EMLO and the State Papers Online to this extensive knowledge base and gain a new perspective on the data.
Charting Birth and Death dates in the Stuart State Papers
The dataset we have constructed from State Papers Online contains very minimal data on each of its subjects: besides a wikipedia link, we’ve only recorded occasional additional details in a notes field. This makes even partial wikidata linkage compelling, because it can generate, for individuals prominent enough to have a wikipedia page at least, some basic stats on who we have and where they are from.
For example, using wikidata one can download a list of birth and death dates for those with wikipedia links. First, download a list of all those on wikidata with a date of birth before 1700 and after 1500 (the Stuart State Papers begin in 1603):
dates_of_birth = query_wikidata("
SELECT DISTINCT ?item ?dateOfBirth ?dateOfDeath ?article
WHERE
{
?item wdt:P31 wd:Q5;
wdt:P569 ?dateOfBirth. hint:Prior hint:rangeSafe true.
?item wdt:P570 ?dateOfDeath.
FILTER('1500-00-00'^^xsd:dateTime <= ?dateOfBirth &&
?dateOfBirth < '1700-00-00'^^xsd:dateTime).
OPTIONAL {
?article schema:about ?item .
?article schema:inLanguage 'en' .
FILTER (SUBSTR(str(?article), 1, 25) = 'https://en.wikipedia.org/')
}
SERVICE wikibase:label { bd:serviceParam wikibase:language 'en'. }
}")This query contains a few more elements:
hint:Prior hint:rangeSafe true. is an optimizer, telling the wikidata query service that the results of ?dob will all be of the same type. It’s needed because the service will time out if the request is so large that it takes more than 60 seconds.
OPTIONAL {
?article schema:about ?item .
?article schema:inLanguage 'en' .
FILTER (SUBSTR(str(?article), 1, 25) = 'https://en.wikipedia.org/')
}This fetches the url for the English-language wikipedia page for each entity (where available), which is what we use to match with the SPO and EMLO datasets.
The query returns a dataset with around 145,000 individuals, plus their wikipedia link and dates of birth/death. The next step is to join this with the list of wikipedia links in our own people information.
I’ve pre-processed two very simple lists, taken from the two datasets on the Networking Archives project, containing the the names of all those who have had Wikipedia entries added to their person record. To match wikidata to the State Papers or EMLO data, I’ll just cross-reference the result of each wikidata query against these lists.
load('/Users/Yann/Documents/Github/blog_notebooks/emlo_wikipedia_links')
load('/Users/Yann/Documents/Github/blog_notebooks/spo_wikipedia_links')
dates_of_birth_joined = dates_of_birth %>% mutate(dateOfDeath = str_remove(dateOfDeath, "T00:00:00Z")) %>%
filter(article %in% spo_wikipedia_links$resource_url) %>%
filter(!is.na(article))
glimpse(dates_of_birth_joined)## Rows: 3,456
## Columns: 4
## $ item <chr> "http://www.wikidata.org/entity/Q65766", "http://www.wiki…
## $ dateOfBirth <dttm> 1605-08-06, 1564-12-31, 1600-01-01, 1620-12-17, 1620-01-…
## $ dateOfDeath <chr> "1673-02-12", "1611-03-02", "1662-01-01", "1652-09-01", "…
## $ article <chr> "https://en.wikipedia.org/wiki/Johann_Philipp_von_Sch%C3%…About 3,000 individuals in the State Papers Online with dates of birth/death have been found. This basic information can be charted, for example:
dates_of_birth_joined %>%
mutate(dateOfBirth = ymd(dateOfBirth)) %>%
mutate(dateOfDeath = ymd(dateOfDeath)) %>%
pivot_longer(names_to = 'type', values_to = 'date', cols = 2:3) %>%
mutate(date = year(ymd(date))) %>%
mutate(date = round_any(date, 10, f = floor) ) %>%
group_by(type,date) %>%
tally() %>%
ggplot() +
geom_col(aes(x = date, y = n, fill = type), alpha = .4, color = 'black', position = 'stack') +
theme_bw() +
theme(legend.position = 'bottom', plot.title = element_text(size = 16, face = 'bold')) + facet_wrap(~type, ncol = 1) + labs(title = "Dates of Birth/Death in the State Papers Online People")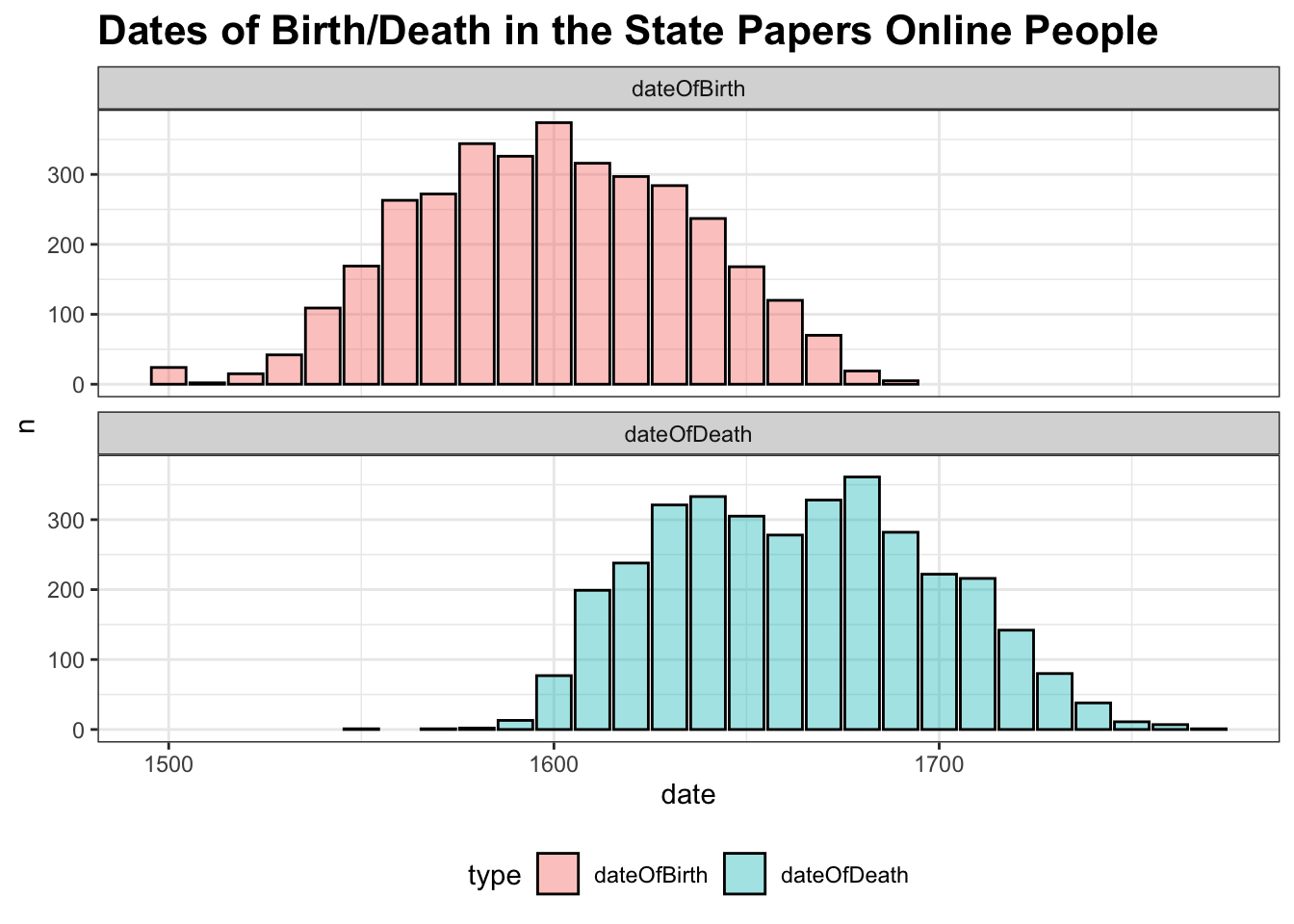
The dates of birth are unsurprising, but I wonder if we are seeing the effects of the English Civil War in the bump in death dates in the 1630s/40s? Many of those found in the State Papers are soldiers, so it is possible.
Mapping Places of Birth and Death
Wikidata also contains geographic information, allowing us to download birthplaces (property P19) where available, along with coordinates (P625) to map them (the method used to draw the map will have to wait for another post).
birthplace = query_wikidata("
SELECT DISTINCT ?item ?article ?place ?placeLabel ?coord
WHERE
{
?item wdt:P31 wd:Q5;
wdt:P569 ?dateOfBirth. hint:Prior hint:rangeSafe true.
FILTER('1500-00-00'^^xsd:dateTime <= ?dateOfBirth &&
?dateOfBirth < '1700-00-00'^^xsd:dateTime)
?item wdt:P19 ?place.
?place wdt:P625 ?coord.
OPTIONAL {
?article schema:about ?item .
?article schema:inLanguage 'en' .
FILTER (SUBSTR(str(?article), 1, 25) = 'https://en.wikipedia.org/')
}
}
")The map below is perhaps surprisingly European: the State Papers data itself is quite narrow, geographically, but many of the letters themselves were written by those born elsewhere - though this does only map a small, elite section of the authors and recipients of letters.
load('/Users/Yann/Documents/Github/blog_notebooks/worldmap')
map = birthplace %>%
filter(article %in% spo_wikipedia_links$resource_url)%>%
filter(!is.na(article)) %>%
mutate(coord = str_remove(coord, "Point\\(")) %>%
mutate(coord = str_remove(coord, "\\)")) %>%
separate(coord, into = c('coordinates_longitude', 'coordinates_latitude'), sep = ' ')
sf_map = map %>%
group_by(placeLabel, coordinates_longitude,coordinates_latitude ) %>% tally() %>%
st_as_sf(coords = c('coordinates_longitude', 'coordinates_latitude'))
sf_map = sf_map %>% st_set_crs(4326)
ggplot() + geom_sf(data = worldmap, lwd = .15) +
geom_sf(data = sf_map,
aes(size = n), alpha = .5, color = 'maroon') +
coord_sf(xlim = c(-10, 40), ylim = c(36, 60)) +
scale_size_area() +
theme_void() + labs(title = "Place of Birth, State Papers Online People") + theme(plot.title = element_text(face = 'bold', size = 16))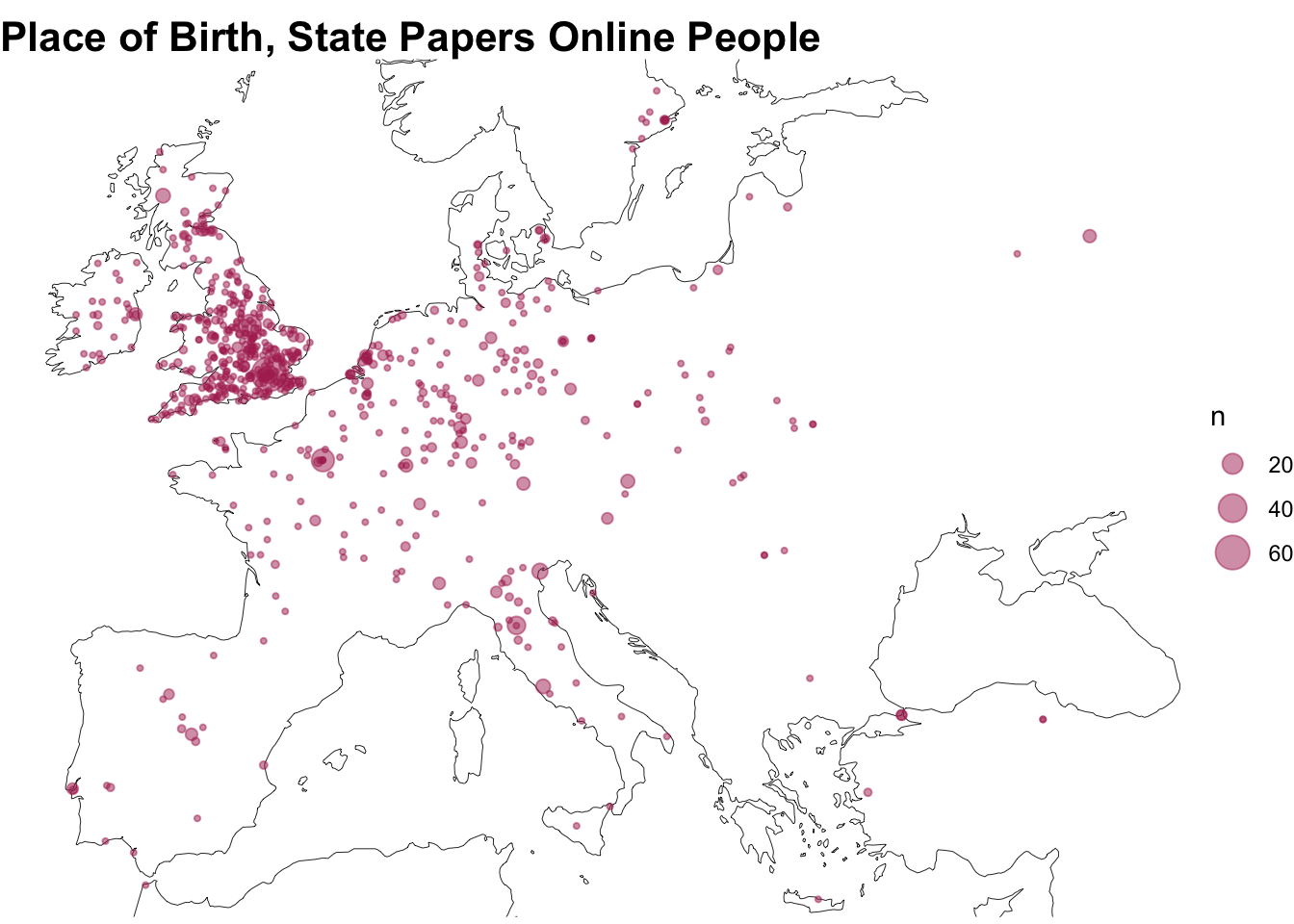
Wikidata also has the property Place of Death (P20), so we can also download that information:
deathplace = query_wikidata("
SELECT DISTINCT ?item ?article ?place ?placeLabel ?coord
WHERE
{
?item wdt:P31 wd:Q5;
wdt:P569 ?dateOfBirth. hint:Prior hint:rangeSafe true.
FILTER('1500-00-00'^^xsd:dateTime <= ?dateOfBirth &&
?dateOfBirth < '1700-00-00'^^xsd:dateTime)
?item wdt:P20 ?place.
?place wdt:P625 ?coord.
OPTIONAL {
?article schema:about ?item .
?article schema:inLanguage 'en' .
FILTER (SUBSTR(str(?article), 1, 25) = 'https://en.wikipedia.org/')
}
}
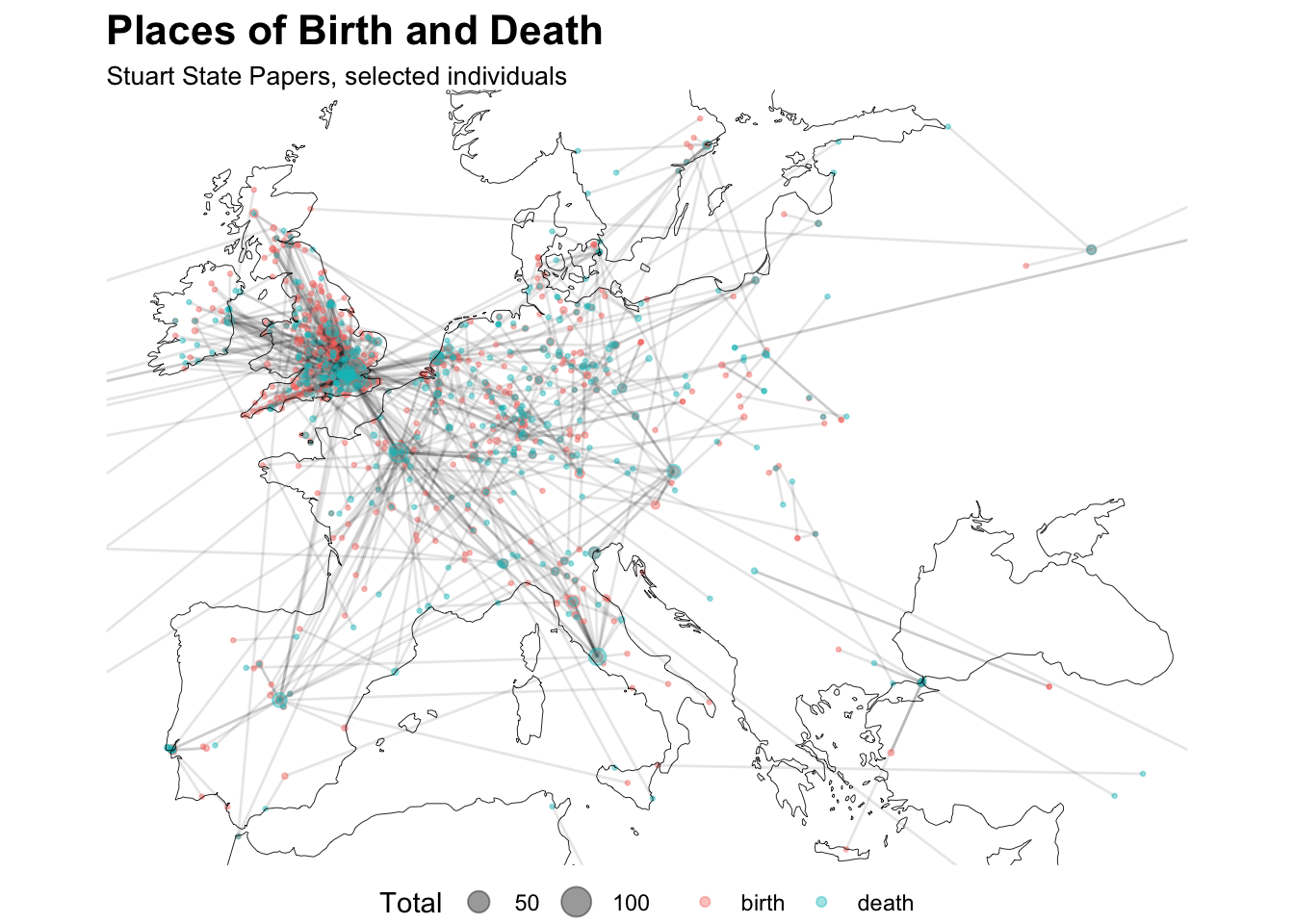
")Mapping both of these, and plotting some lines running from each individual’s place of birth to their place of death shows that, unsurprisingly, ‘prominent’ individuals (those with Wikipedia pages) in the State Papers tended to migrate towards capital cities - there are clear lines moving towards London, Paris, Madrid, Rome, and Amsterdam.
Make a master list of birth/death places:
places_of_birth_death = birthplace %>%
left_join(deathplace, by = 'item') %>%
filter(article.x %in% spo_wikipedia_links$resource_url) %>%
filter(!is.na(article.x)) %>%
mutate(birthplace_coord = str_remove(coord.x, "Point\\(")) %>%
mutate(birthplace_coord = str_remove(birthplace_coord, "\\)")) %>%
separate(birthplace_coord, into = c('bp_coordinates_longitude', 'bp_coordinates_latitude'), sep = ' ') %>%
filter(!is.na(article.y)) %>%
mutate(deathplace_coord = str_remove(coord.y, "Point\\(")) %>%
mutate(deathplace_coord = str_remove(deathplace_coord, "\\)")) %>%
separate(deathplace_coord, into = c('dp_coordinates_longitude', 'dp_coordinates_latitude'), sep = ' ') Use the sf packages to turn this into two separate datasets of points and spatial lines:
points = places_of_birth_death %>%
mutate(id = 1:nrow(.)) %>%
mutate(birth = paste0(bp_coordinates_longitude, ";", bp_coordinates_latitude)) %>% mutate(death = paste0(dp_coordinates_longitude, ";", dp_coordinates_latitude)) %>%
pivot_longer(names_to = 'type', values_to = 'coordinates', cols = 15:16) %>% separate(coordinates, into = c('coordinates_longitude', 'coordinates_latitude'), sep = ';')
lines = points %>%
st_as_sf(coords = c('coordinates_longitude', 'coordinates_latitude')) %>%
group_by(id) %>%
dplyr::summarise(m = n(),do_union = FALSE)%>%
st_segmentize(units::set_units(10, km))%>%
st_cast('LINESTRING')## `summarise()` ungrouping output (override with `.groups` argument)lines = lines %>% st_set_crs(4326)
points_tallied = points %>%
group_by(type,coordinates_longitude,coordinates_latitude) %>%
tally() %>%
st_as_sf(coords =c('coordinates_longitude', 'coordinates_latitude') )
points_tallied = points_tallied %>%
st_set_crs(4326)Draw the map:
ggplot() +
geom_sf(data = lines, alpha = .1) +
geom_sf(data = points_tallied, aes(color =type, size= n), alpha = .4)+
geom_sf(data = worldmap, lwd = .15) +
coord_sf(xlim = c(-10, 40), ylim = c(36, 60)) +
scale_size_area() +
theme_void() +
labs(
size = 'Total',
color = NULL,
title = "Places of Birth and Death",
subtitle = "Stuart State Papers, selected individuals"
) +
theme(
plot.title = element_text(size = 16, face = 'bold'),
plot.subtitle = element_text(size = 10),
legend.position = 'bottom'
)
Again, these queries can be built up, and one piece of data connected to another. A list of all those with parents born in different country to their birth place would be an interesting starting-point for understanding a second-generation diaspora network.
Wikidata and EMLO
Early Modern Letters Online already has good basic, structured biographical data, and wikidata isn’t going to add much there. But the knowledge graph contains other, more detailed structured information (such as membership lists), and combining queries allows us to filter on very specific pieces of information using the power of linked data.
Wikidata’s data on family relations helps us to construct complex queries about family trees. We can ask, for example - how many letter authors (or recipients) in EMLO have parents who were at some point imprisoned? This following query will get us a list of everyone with the property ‘imprisoned’ on wikidata, plus all of their children.
rs_q = query_wikidata ("SELECT DISTINCT ?itemLabel ?childLabel ?article ?valueLabel ?dob WHERE
{
?item wdt:P2632 ?value.
?item wdt:P40 ?child.
?child wdt:P569 ?dob.
OPTIONAL {
?article schema:about ?child .
?article schema:inLanguage 'en' .
FILTER (SUBSTR(str(?article), 1, 25) = 'https://en.wikipedia.org/')
}
SERVICE wikibase:label { bd:serviceParam wikibase:language 'en'. }
}")Breaking this down:
SELECT DISTINCT ?itemLabel ?childLabel ?article ?valueLabel ?dob WHERE listing all the pieces of information we’d like.
?item wdt:P2632 ?value. Get all the items with the property value P2632 (place of detention). Store the person as ?item and the entity for the place of detention as ?value.
?item wdt:P40 ?child. Get all those with the property P40 (child) for each ?item above
?child wdt:P569 ?dob. Get their dates of birth (for filtering)
Again, cross-reference this list against a master list of wikipedia IDs for people on EMLO:
library(flextable)
rs_q %>%
filter(article %in% emlo_wikipedia_links$resource_url) %>%
filter(!is.na(article)) %>%
select(person = childLabel, parent = itemLabel) %>% flextable() %>% theme_vanilla() %>% autofit() %>% fit_to_width(max_width = 10)person | parent |
Anne Bacon | Anthony Cooke |
Algernon Percy, 10th Earl of Northumberland | Henry Percy, 9th Earl of Northumberland |
Cardinal de Bouillon | Frédéric Maurice de La Tour d'Auvergne |
Mary Dudley, Lady Sidney | John Dudley, 1st Duke of Northumberland |
Mary Dudley, Lady Sidney | Jane Dudley, Duchess of Northumberland |
George Legge, 1st Baron Dartmouth | William Legge |
Margaret Roper | Thomas More |
Thomas Wentworth, 5th Baron Wentworth | Thomas Wentworth, 1st Earl of Cleveland |
John Dudley, 1st Duke of Northumberland | Edmund Dudley |
Thomas Wriothesley, 4th Earl of Southampton | Henry Wriothesley, 3rd Earl of Southampton |
Henry Percy, 9th Earl of Northumberland | Henry Percy, 8th Earl of Northumberland |
Alethea Howard, Countess of Arundel | Mary Talbot, Countess of Shrewsbury |
John Malet | Thomas Malet |
Carew Raleigh | Walter Raleigh |
Mildred Cooke | Anthony Cooke |
Charles Bruce, 3rd Earl of Ailesbury | Thomas Bruce, 2nd Earl of Ailesbury |
Edward Montagu, 2nd Baron Montagu of Boughton | Edward Montagu, 1st Baron Montagu of Boughton |
Sir James Langham, 2nd Baronet | Sir John Langham, 1st Baronet |
Sir James Langham, 2nd Baronet | Sir John Langham, 1st Baronet |
Thomas Paget, 3rd Baron Paget | William Paget, 1st Baron Paget |
Robert Phelips | Robert Phelips |
Horace Walpole | Robert Walpole |
William Wentworth, 2nd Earl of Strafford | Thomas Wentworth, 1st Earl of Strafford |
Wikidata has found thirty, including Carew Raleigh, son of Walter Raleigh, and Horace Walpole, whose father, Robert, was imprisoned in the Tower for 6 months in 1712 for ‘venality’, as well as Henrietta Goldolphin - her father, John Churchill, first Duke of Marlborough was imprisoned in the Tower in 1692, accused of signing a letter calling for the restoration of James II.
Linking letters in the State Papers Online to wikidata
With these links we can query wikidata and then pass the results to the State Papers metadata. This query, for example, downloads a list of all descendants of James VI of Scotland/James I of England, with a wikipedia page:
jamesdesc = query_wikidata('SELECT DISTINCT ?human ?humanLabel ?dob ?article
WHERE
{
wd:Q79972 wdt:P40/wdt:P40* ?human .
?human wdt:P31 wd:Q5 .
OPTIONAL{?human wdt:P569 ?dob .}.
FILTER( ?dob < "1700-00-00"^^xsd:dateTime).
?article schema:about ?human .
?article schema:inLanguage "en" .
FILTER (SUBSTR(str(?article), 1, 25) = "https://en.wikipedia.org/").
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en" }
}')Then we can pull out all the letter records in SPO where the sender and recipient is in this list:
spo_ids = rbind(spo_mapped_people %>% select(id = X1, wikilink = X5), spo_added_people %>% select(id = X1, wikilink = `Linked data (if any)`)) %>%
filter(wikilink %in% jamesdesc$article) %>%
filter(!is.na(wikilink))
james_network = spo_raw %>% filter(X1 %in% spo_ids$id & X2 %in% spo_ids$id) %>% distinct(X1, X2) %>% graph_from_data_frame() %>%
as_tbl_graph() %>%
left_join(spo_mapped_people %>%
mutate(X1 = as.character(X1)),
by = c('name' = 'X1'))And finally, turn this into a network:
james_network %>%
ggraph() +
geom_node_point() +
geom_edge_link(alpha = .3) +
geom_node_text(aes(label = X2), repel = T, size = 2) +
theme_void()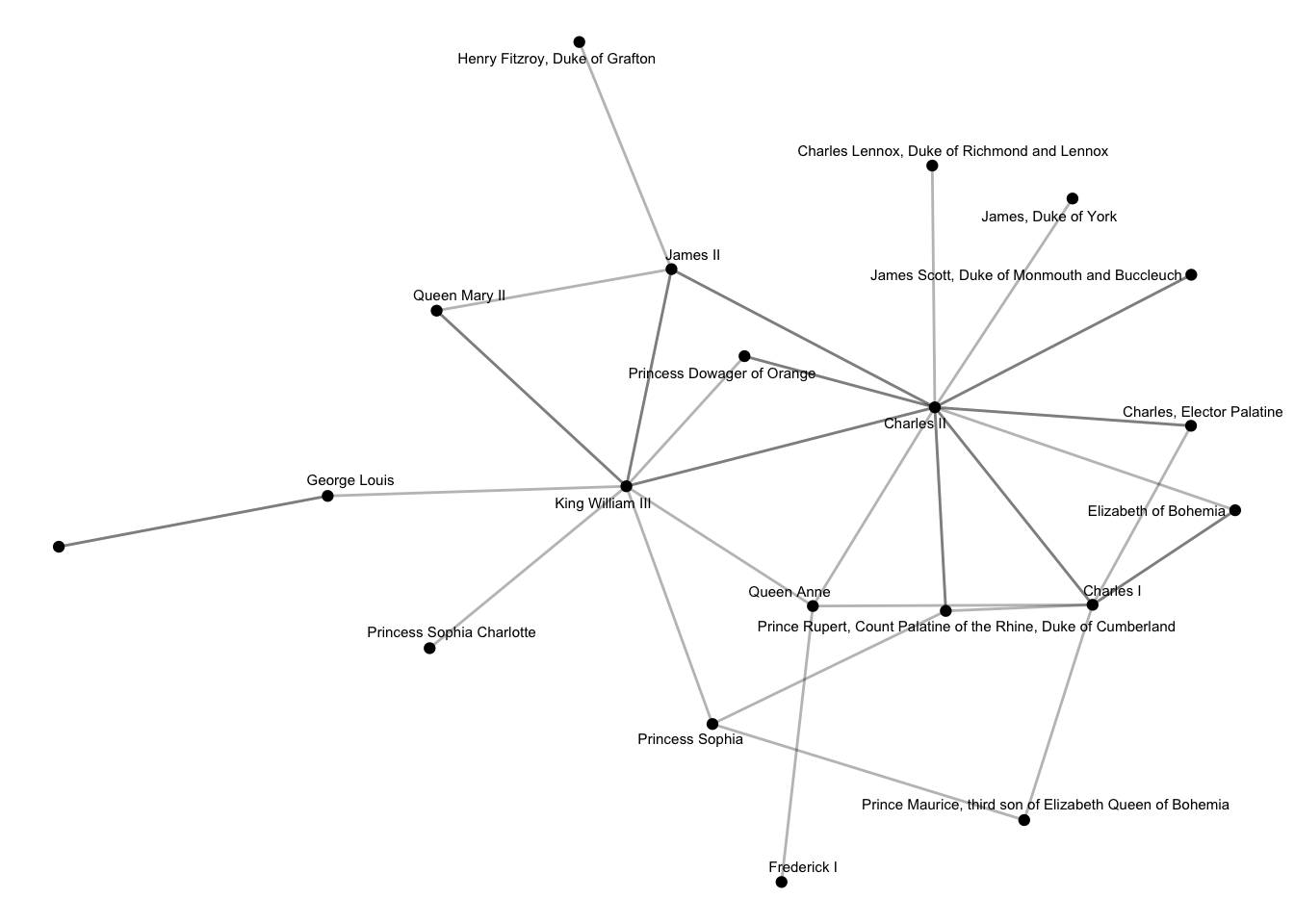
Some Conclusions
I hope this has shown how Wikidata can add some value as both a way to populate a sparse correspondence dataset with basic metadata, and a way to construct complex queries to highlight groups of individuals in that data. It’s important to note that wikidata does not claim to store facts in itself: at its core, wikidata aims to be a repository for knowledge from elsewhere - rather than storing the birth date of, say Henry Oldenburg, wikidata hopes to store the fact that, say, the Oxford Dictionary of National Biography records his birth year as 1619.
This subtle difference is important, because it means that wikidata is only as good as the references which make it up. Is it ultimately any use for scholarly work? As we’ve seen, only a small fraction (4,500 out of 30,000) of individuals in the State Papers have been linked to a wikipedia page, so this can only, at the moment, give us additional metadata on relatively prominent individuals.
However, one can easily see how this same data structure could be used to store much richer information about individuals, and build interesting and complex queries. Connecting this knowledge graph directly to the State Papers metadata, with letters added as entities and properties such as ‘written by’ and ‘language’ would make it much more useful - one could, for example, directly query a knowledge graph and ask for ‘all letters written in French, sent by a relative of a monarch’, or, ‘all letters written by descendants of Louis XIV’.
Further Reading
Official Wikidata SPARQL tutorial - definitely the best starting-point for learning how the service works.
Wikidata SPARQL query service examples - a page with tonnes of examples of queries. Again, very useful as starting-points for making your own.